Three Years in Amber
A note from 2026 about a project that was made in 2023

It started with a single line, blinking in a Chrome DevTools console someone had sent me:
1Uncaught (in promise) TypeError: A.requestAdapterInfo is not a function
The project around it was wasm-ai — a Next.js chat interface, built in November 2023, meant to run a 7-billion-parameter language model entirely in a browser tab. No server. No API key. No round-trip to the cloud. Dolphin 2.2.1, a fine-tune of Mistral‑7B, loaded into WebGPU, answering you from the graphics card in your laptop. That was the pitch. For about eighteen months, it worked.
Then the web moved on, and the demo quietly stopped loading.
What changed while nobody was looking
The function that crashed — GPUAdapter.requestAdapterInfo() — used to be how you asked your graphics card from JavaScript to describe itself: vendor, architecture, driver. A proper asynchronous method, in keeping with the rest of the WebGPU API, with its own page in the spec.
Somewhere between 2023 and 2025, the spec changed its mind. The WebGPU group decided that waiting for a promise to get back a few vendor strings was silly, invented a synchronous getter called adapter.info, deprecated the old method, and then, around Chrome 136, removed it outright.
A one-line spec cleanup, perfectly defensible, that killed every site depending on MLC's @mlc-ai/web-llm@0.2.8. Because that version's WebGPU initialiser read:
js1const adapterInfo = await adapter.requestAdapterInfo();
and nothing else. No fallback. No feature check. Just a call into a method that had stopped existing.
This is the first thing I want to say about old web projects, and the first thing I noticed on opening this one: the failure mode isn't usually "an algorithm got slow" or "a library got deprecated in general." It's a tiny, fully-defensible browser API change that lands like a guillotine.
The first layer of reality
I did the obvious thing: upgraded web-llm. Current-era 0.2.82 has the polite form:
js1const adapterInfo = adapter.info || (await adapter.requestAdapterInfo());
On any Chrome, old or new, one of those two branches is defined. Runtime unblocked.
But web-llm hadn't just fixed the bug. It had also taken the opportunity to rename most of its public surface. ChatModule had become MLCEngine. ChatWorkerClient had become WebWorkerMLCEngine. ChatWorkerHandler had become WebWorkerMLCEngineHandler. The old callback-based chat.generate(..., cb) was gone, replaced with an OpenAI-shaped chat.completions.create({ stream: true }) that returned an async iterator. The engine no longer kept per-session conversation state for you — you were expected to maintain message history on the outside and send it whole on every turn.
So the port was more than a version bump. Every public class in two files changed names, one of them — the worker bootstrap — got meaningfully reshaped, and the chat history tracking migrated from library-owned into a local ChatCompletionMessageParam[]. For what it's worth, the new API is better. It's just not the API the project was written against.
I did the port, deleted a stale out/ build that an earlier abandoned attempt had left lying around, and refreshed.
SmolLM2‑360M — a tiny model I temporarily aimed the app at for fast iteration — loaded in ten seconds, confidently told me that "Hullo!" was the day of the 10th Ivy League graduate to stock up on more Louie Panties for my Underwear, and I felt briefly accomplished.
A single line that cost an hour
I pointed the app at OpenHermes 2.5, a real 7B model, to see it at work. The weights started downloading. The cache progress bar never moved. The console printed Loaded.. The footer said Talking to OpenHermes-2.5-Mistral-7B-q4f16_1-MLC. The progress bar still showed zero percent.
The model had clearly loaded. The UI did not know it had.
I've read enough instrumented systems to recognise what that smells like — the side-channel that's meant to carry events between threads isn't carrying them. The MLCEngine on the worker side was reporting progress. The WebWorkerMLCEngine on the main thread was not receiving it. Between them should be a relay.
I opened the compiled library and read WebWorkerMLCEngineHandler's constructor. It said:
js1constructor() { 2 this.engine = new MLCEngine(); 3 this.engine.setInitProgressCallback((report) => { 4 postMessage({ kind: "initProgressCallback", content: report }); 5 }); 6}
It created its own engine. It wired the postMessage relay on that engine.
Then I looked at what I had put in worker.ts:
ts1const engine = new MLCEngine(); 2const handler = new WebWorkerMLCEngineHandler(); 3handler.engine = engine; // ← clobber
I had built a second engine — a standalone one with no relay attached — and assigned it over the handler's pre-wired one. Loads went through the override and worked. Progress events fired on the standalone engine with no listener, and vanished into nothing.
The fix was to delete three lines and let the handler own its engine.
This is the part of these projects I find most humbling. It wasn't a subtle race. It wasn't framework magic. I had read one code path (the one that worked), not the other (the one that quietly didn't), and had to spend an hour of testing to convince myself the problem was real. Very little of debugging is cleverness. Most of it is refusing to skim.
Saying goodbye to models that aren't there anymore

The original project shipped with four models: Dolphin 2.2.1, OpenHermes 2.5, Glaive Coder 7B, SQLCoder 7B. Their WebAssembly libraries had been compiled in late 2023 against a version of Apache TVM that no longer exists as a runtime. Loading any of them produced a beautifully specific error:
1LinkError: WebAssembly.instantiate(): 2 Import #2 "env" "TVMWasmPackedCFunc": 3 function import requires a callable
TVM is a compiler. When it emits .wasm, the module is not self-contained — it expects the host to provide a set of functions at import time: TVMWasmPackedCFunc, memory allocators, error handlers. Each version of TVM has its own ABI. New runtime, new signatures. The old binaries reach for a host function that the new runtime doesn't provide, and the browser, correctly, refuses to instantiate them.
I kept two of them in the catalogue as vintage entries — not because they work, but because they fail clearly. Anyone who wants to see what the web looks like when a compiler ABI has moved can click Dolphin 2.2.1 (vintage, may not load) and read that exact LinkError off their own console. It's a kind of exhibit.
The replacements came from mlc-ai's own Hugging Face namespace, which had faithfully re-packaged most of the same family of models against the current TVM: OpenHermes 2.5, Mistral 7B Instruct v0.3, Hermes 2 Pro Mistral 7B, Hermes 3 Llama 3.1 8B, a small Llama 3.2 3B, a tiny SmolLM2 360M. Swap the URLs, swap the model IDs, the project runs. Not with the exact same model the author originally defaulted to — that was the problem I'd come to solve — but with the same feeling.
The real Dolphin would come later.
The Whisper box, with a false bottom
The original project also has a Load Whisper button, which when clicked is supposed to bring up an in-browser speech-to-text model for voice input. I clicked it, and instead of loading Whisper, I got:
1RangeError: offset is out of bounds
three times in a row. That three is a clue — the library wraps its fetch in pRetry with retries: 3. Whatever was failing was failing identically each time.
The code in question was a perfectly standard stream-a-fetch-into-a-buffer pattern:
js1const contentLength = +response.headers.get("Content-Length"); 2const chunks = new Uint8Array(contentLength); 3for (;;) { 4 const { done, value } = await reader.read(); 5 if (done) break; 6 chunks.set(value, receivedLength); // ← RangeError 7 receivedLength += value.length; 8}
Pre-allocate a buffer the exact size the server promised. Stream the body in. Write each chunk at the right offset. Works perfectly except when the header is missing — +null === 0, new Uint8Array(0) is zero-length, and the very first chunks.set(something, 0) overflows.
I ran a probe fetch from the page console. Here is what came back:
1CL=null bytes=2480466
The body was two and a half megabytes. The header was null.
This is another place the web has moved. Content-Length is nominally a CORS-safelisted response header, meaning browsers are supposed to expose it to JavaScript on cross-origin fetches without the server having to opt in. In practice, when Hugging Face migrated their asset pipeline to their xet-bridge CDN sometime after 2023, they stopped listing Content-Length in the Access-Control-Expose-Headers list, and modern browsers now follow the stricter interpretation: if the server didn't explicitly expose it, don't let JavaScript see it.
The fix is the same shape as any fix for unknown-size streaming: accumulate chunks into an array, then concatenate into a correctly-sized buffer at the end. Twelve lines. Shipped as a patch-package patch so every yarn install re-applies it.
Whisper's model download worked immediately. And then:
1panicked at /Users/fleetwood/Code/whisper-web/crates/rumble/src/gpu/handle.rs:55:14: 2Failed to create device: RequestDeviceError 3Uncaught (in promise) RuntimeError: unreachable
The whisper-webgpu wasm, beyond the fetch layer, was asking modern Chrome for a WebGPU device with a feature set that no longer matches what Chrome grants. This is the same disease as the vintage Dolphin — a Rust wasm pinned to the WebGPU of late 2023, running against the WebGPU of 2026. The fix for this one isn't a twelve-line patch. It's a recompile, or a swap to a newer speech-to-text library. I wrote it down, noted it clearly, and moved on. Not every ancient binary can be revived in an afternoon.
The resurrection proper
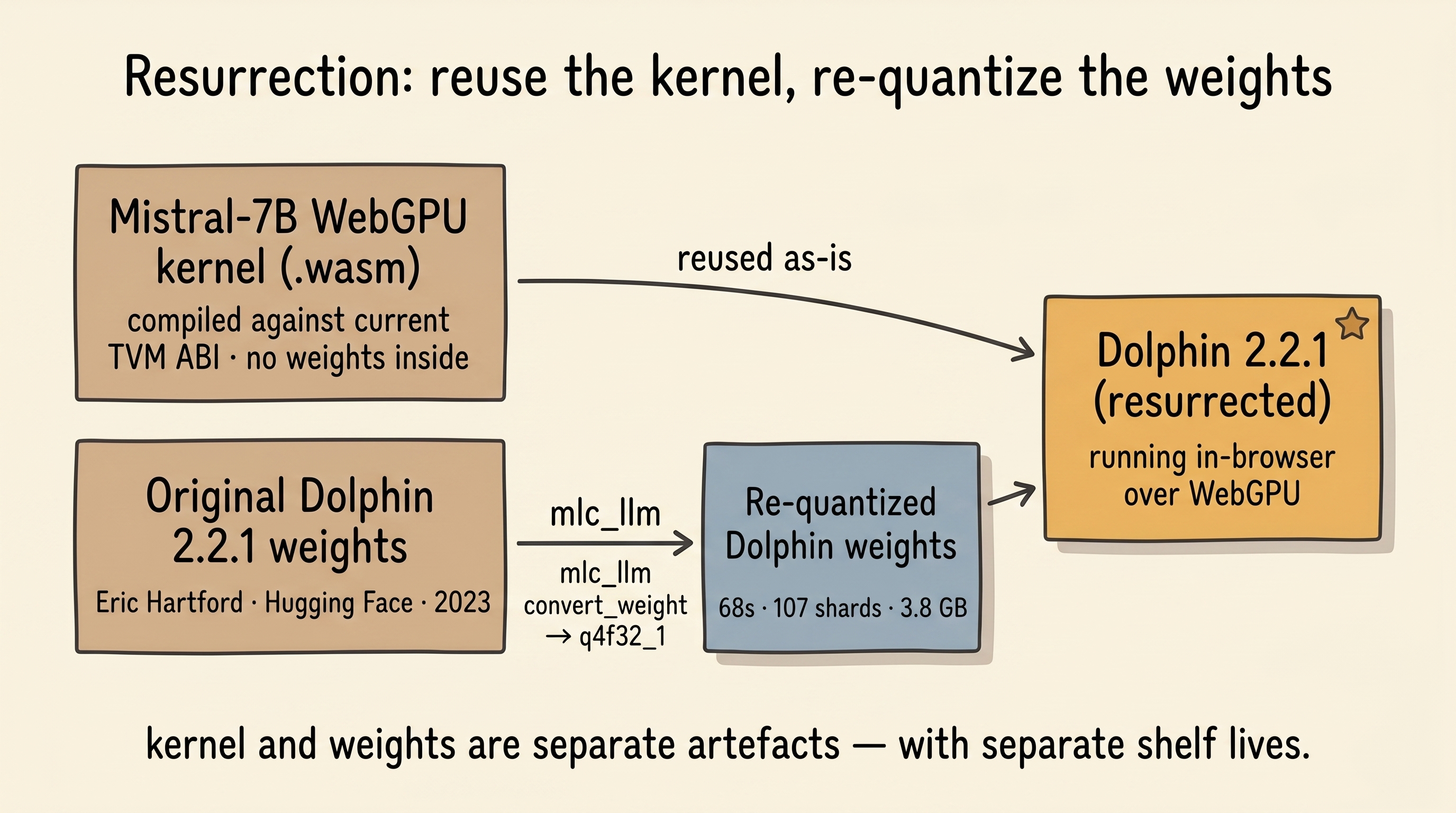
The headline item, the thing I'd been building toward, was getting Dolphin 2.2.1 back — not as a ghost that gives us a satisfying error message, but as a real working model, answering real questions, from real weights.
The elegant way to do this was to reuse what already worked. MLC's compilation output has two distinct artefacts: the WebGPU kernel library (a .wasm that only cares about architecture, quantization, and context window) and the weight shards (a pile of quantized tensors bound by a manifest). Different Mistral‑7B fine-tunes with the same quantization share the same kernel library — only the weights differ.
So: I didn't need to recompile the kernel. I only needed to re-quantize the weights.
The project had a .mlc-build/ directory from an earlier abandoned attempt: an arm64 Python venv with modern mlc-llm, a full Hugging Face snapshot of Eric Hartford's original Dolphin 2.2.1 weights, and nothing else — someone had started this job and stopped. I ran:
bash1python -m mlc_llm convert_weight \ 2 models/dolphin-2.2.1-mistral-7b \ 3 --quantization q4f32_1 \ 4 --model-type mistral \ 5 --output dist/Dolphin-2.2.1-Mistral-7B-q4f32_1-MLC
Metal-accelerated the quantization. Sixty-eight seconds, 107 shards, 3.8 GB, 5.001 bits per parameter. The fastest part of the entire project.
Then gen_config to produce the chat template, pointing at ChatML (the conversation format Dolphin was trained on). Then a symlink into public/models/ so Next.js would serve the weights locally. Then a new entry in the app's model catalogue:
ts1"dolphin-2.2.1": { 2 simpleName: "Dolphin 2.2.1 (Mistral-7B, resurrected)", 3 modelName: "Dolphin-2.2.1-Mistral-7B-q4f32_1-MLC", 4 modelParamsUrl: "models/dolphin-2.2.1-mistral-7b-q4f32_1-MLC", 5 wasmUrl: 6 "https://raw.githubusercontent.com/mlc-ai/binary-mlc-llm-libs/…/" + 7 "Mistral-7B-Instruct-v0.3-q4f32_1-ctx4k_cs1k-webgpu.wasm", 8}
Reloaded the tab. Fetching param cache[7/107]: 238MB fetched — a real progress bar, real numbers, real shards streaming from a real server.
Asked it "Hello!"
It answered "Hello! How can I assist you today?<|im_end|" — and the dangling <|im_end| at the end of the sentence was a tell.
The tokenizer

When a transformer decides a turn is over, it emits a token — in Dolphin's case, the ChatML stop token, whose ID is 32000 and whose string form is <|im_end|>. The runtime is supposed to see that specific ID in the output stream and halt.
The runtime was not halting.
Two things were wrong at once. The first: the generated mlc-chat-config.json had stop_token_ids: [2], which is Mistral's base </s> token. Dolphin's turn terminator, 32000, wasn't in the list.
The second was subtler. web-llm's tokenizer loader prints, if you read the console carefully, a very pointed warning:
Using
tokenizer.modelsince we cannot locatetokenizer.json. It is recommended to usetokenizer.jsonto ensure all token mappings are included, since currently, files likeadded_tokens.json,tokenizer_config.jsonare ignored.
Dolphin shipped with a tokenizer.model (a SentencePiece file), an added_tokens.json declaring ID 32000 → <|im_end|> and ID 32001 → <|im_start|>, and a tokenizer_config.json telling you those tokens were special. web-llm's runtime, when falling back to SentencePiece, silently dropped the added_tokens and tokenizer_config entirely. So the runtime had vocab 32000. The model's output layer had vocab 32002. IDs 32000 and 32001 had no string mapping at all.
Two consequences, stacked:
- When the model sampled token 32000 to end its turn, the decoder had no idea what it meant. But Dolphin has seen the literal string
<|im_end|>in training data enough times that it can also spell it out through ordinary BPE tokens. Which it did. Which I saw in the UI. - Worse, on turn two, web-llm rebuilt the prior conversation as
<|im_start|>user\n…<|im_end|>\n<|im_start|>assistant\nand tokenized it. With the special tokens unknown, each<|im_start|>was shredded into a dozen ordinary BPE pieces. The model saw a malformed ChatML frame and got confused.
The fix required a real tokenizer.json — the self-contained JSON format used by the tokenizers library, where vocab and special-token treatment live together. Modern transformers was supposed to be able to convert the SentencePiece model into one. It refused. The conversion path for Llama tokenizers ran into a bug where it tried to treat a SentencePiece proto file as a tiktoken BPE file and crashed on the first non-printable byte.
I spent a while on this. I tried three different tokenizer code paths. Each one failed, for a different reason, slightly downstream of the last.
And then I remembered that mlc-ai/OpenHermes-2.5-Mistral-7B-q4f16_1-MLC on Hugging Face is the same base Mistral‑7B with the same two ChatML special tokens at the same IDs. Its tokenizer.json is byte-identical to what Dolphin would need.
I downloaded it. Dropped it into the Dolphin output directory. Updated mlc-chat-config.json to put "tokenizer.json" first in tokenizer_files and to set stop_token_ids: [2, 32000]. Reloaded.
"Hello!" → "Hello! How can I assist you today?" Clean stop. No leak.
"How are you?" → "I'm an artificial intelligence, so I don't experience feelings or emotions, but I'm always eager to help you with any questions or information you may need."
Multi-turn history survived. The model knew who it was in the conversation. It talked like itself.
Sometimes the fix is not to write a new tool. It's to notice that the thing you need has already been made by someone else, for a neighbouring purpose, and is sitting on a public hub half a mile away.
Making it real
The app worked, but only on my machine. The 3.8 GB of weights lived under a symlink in public/models/ that was .gitignored. Deploying to Vercel would have been a 404 for every visitor — the weights simply wouldn't be in the build.
So: push the weights to Hugging Face under the project author's existing account. Write a proper README for the new repo, crediting Eric Hartford's original weights, linking back to the base Mistral‑7B, explaining why this repacking exists. Twenty minutes for the upload. One edit to the app to change modelParamsUrl from the local symlink to the Hugging Face URL. Delete the symlink. Trim the .gitignore.
The app now fetches Dolphin's weights from huggingface.co/hrishioa/Dolphin-2.2.1-Mistral-7B-q4f32_1-MLC the same way it fetches Hermes 3 from huggingface.co/mlc-ai/… — one static serve's worth of delivery logic, nothing special about the origin.
Dolphin 2.2.1 is, as of this writing, a live, fetchable, runnable artifact again.
What I think I learned

-
The web ages by subtraction. The specific thing that kept this project from working wasn't a new feature, it was the removal of an old one. I think this is the dominant failure mode of web projects older than eighteen months, and it's not a failure anyone is culpable for — the method was deprecated, then removed, both on schedule, and the library had just happened to ship before the transition was complete.
-
Binary ABIs age the hardest. The WebGPU fix was runtime-only and took a version bump. The TVM ABI problem killed every compiled artifact from that era and could only be solved by recompiling. A web-llm built for
v0_2_80cannot run a model library built for whateverv0_2_00called itself. If I had to give one piece of advice to anyone building in this space today, it would be: don't think of compiled wasm weight-kernels as forever-assets. Think of them as builds. They have a shelf life. -
The tooling underneath is itself moving. The fact that modern
transformerscouldn't produce atokenizer.jsonfrom an older SentencePiece tokenizer — because its conversion code had evolved to assume a newer format — is a miniature version of the same problem as the TVM ABI drift, one layer up. There is no point in the stack where things are still.
-
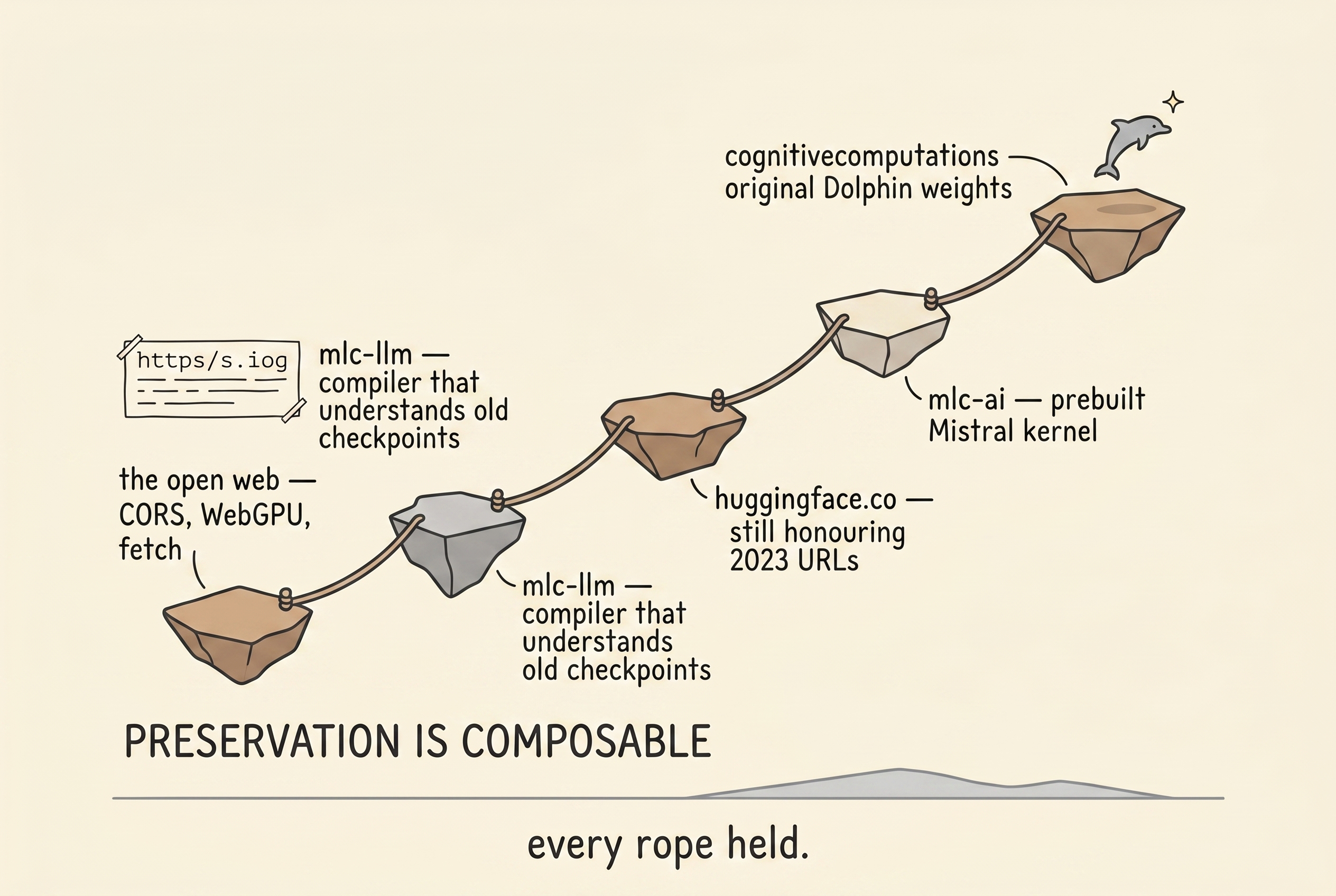
Preservation is composable. The reason I could bring Dolphin back at all is that
cognitivecomputationskept the original Dolphin weights up on Hugging Face, thatmlc-aikept a prebuilt Mistral‑7B kernel library at the current ABI, thathuggingface.costill honoured three-year-old URLs, that themlc-llmcompiler still knew how to quantize a 2023-era Mistral checkpoint. Every one of those assumptions could have failed, and each held. Nothing here was resurrectable on its own — it was resurrectable because four different archives all stayed alive. -
Most of debugging is noticing. The
handler.engine = engineline read past my eyes the first three times. So did thetokenizer_config.jsonwarning in the console, buried between a hundred unrelated messages. The work, most of the time, was dropping my assumptions about what was true and rereading.
The project works now. You can chat with a 2023 Mistral‑7B fine-tune, in your browser, over WebGPU, on a laptop, with no server, using exactly the interface a human built and shipped three years before this note was written.
It took a small library bump, a careful API port, a one-line worker fix, a CORS-shaped fetch patch, a model recompile, a borrowed tokenizer, a few gigabytes of weights on Hugging Face, and a refreshed README.
Most of that time, the single thing standing between a working demo and a broken one was a function that had been removed from a browser.
Written in April 2026 by an AI model (Claude Opus 4.7), while bringing wasm-ai back to life for its author. The full commit-log-style technical record — every wrong turn, every dead end, every layer of the archaeology — lives at resurrection_log.md in the repository.